|
:: 게시판
:: 이전 게시판
|
- 자유 주제로 사용할 수 있는 게시판입니다.
- 토론 게시판의 용도를 겸합니다.
통합규정 1.3 이용안내 인용"Pgr은 '명문화된 삭제규정'이 반드시 필요하지 않은 분을 환영합니다.법 없이도 사는 사람, 남에게 상처를 주지 않으면서 같이 이야기 나눌 수 있는 분이면 좋겠습니다."
15/04/08 23:26
결과적으로 training set의 수와 학습속도를 기하급수적으로 늘려서, training set만이 갖고 있는 bias를 제거시킨 셈이네요. 그런데 정확도를 증가시키기 위해 필요한 training set의 개수가 어떤 식으로 커질지 궁금하네요. 지수적으로 커지면 결국 또 정확도의 한계가 있을 것 같은데...
아무튼 잘 읽었습니다. 말씀하신 대로라면 알고리듬적인 면에서 더 발전을 기대하기보다는 새로운 응용분야를 탐색하는 쪽이 맞는 것 같아요. 저는 번역 쪽에 썼으면 좋겠다는 생각이 드네요.
15/04/08 23:36
음성인식에 사용된 data set 은 구글의 경우에는 약 500시간 정도, 영상인식을 위해 사용된 사진은 42M 장 정도라고 했던걸로 기억합니다.
기억이 가물가물하네요. 말씀하신 번역분야 에 대한 시도도 아주 활발한 편입니다.
15/04/08 23:55
이미 구글번역기는 100% 빅데이터 분석에 의해 돌아가고 있습니다. 언어학자가 아예 참여를 안했다죠? 아래는 관련 기사입니다.
http://www.etnews.com/201309150165 구글의 무서움은, 구글이 수집한 데이터의 양이 어마어마하다는데 있습니다. 그야말로 빅데이터. 세계 최고의 검색엔진을 보유한 회사 답게, 그 수집한 데이터를 이용하여 여러 분야에 활용하고 있지요. 문장검색만이 아닌 이미지 검색, 동영상 검색, 음악 검색... 등이 가능해진것도 그 이유고요.
15/04/09 00:11
구글번역기는 Statistical Machine Translation 방식입니다.
빅데이터를 사용하는 것은 맞지만, 제가 알기로는 아직 DNN을 번역에 적용한 상용 버전은 없는 걸로 알고 있습니다.. 아직은 NLP쪽에서는 DNN을 활용하기 시작한 상태이고, 1~2년 전부터 관련 논문은 많이 나오기 시작하는데, 눈에띄는 성과는 없는 것으로 알고 있습니다. RRNN이라는 좀 특이한 구조를 만들어서 번역 성능을 끌어올린 논문은 봤습니다만, 영/중 번역용이라, 한/영 번역등에서 SMT가 잘 해결하지 못하는 문제에 대한 근본적인 해결은 안될 것 같습니다.
15/04/09 00:16
감사합니다. 제가 인공지능 분야에 대해서는 깊이가 없어서...
음... 구글번역기는 아직까지는 기계번역 수준에 머물고 있는 거였군요. 조금 실망이네요... 췟... '3'
15/04/09 00:26
아닙니다! 틀린 말씀은 아니셨습니다. SMT도 엄연히 빅데이터를 사용하니까요!
다만 개인적으로 DNN으로 번역은 조금 회의적으로 보는게, 개도 사물을 구분하고 소리를 구분합니다만, 번역을 하지는 못하거든요.... (사람도 겨우 하는건데요) 그런데 NHN 김정희 부장은 음성인식의 통짜 DNN보다, 번역 통짜 DNN이 더 빨리 나올거 같다고 하시더라구요. (어쨌든 우리나라 DNN 전문가이시니,,, 왜 그런지는 저도 매우 궁금합니다........)
15/04/08 23:57
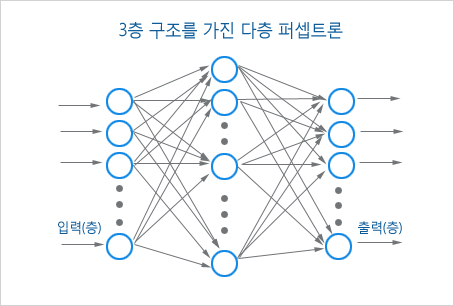
여기서 Deep이란 여러개의 Hidden Layer를 "깊게" 쌓아 올린 것을 말합니다.
죽어있던 ANN을 Hinton 교수 외 몇몇 대가들이 Pre-training을 도입하면서 또 다른 돌파구를 제시한게 지금 딥러닝의 핵심이지요. 결국 Pre-training이 다시한번 붐을 일으켰지만, 요새는 그닥 쓰이지 않는 추세이고, Mini-batch, Drop-out이나 Training set의 순서를 적당히 섞어주는 Randomness를 추가함으로써, 훈련이 더 효율적으로 되도록 합니다. 뭐 사실 NHN의 김정희 부장의 강연을 보면 다 필요없고 데이터의 양과 GPU의 연산속도가 중요하다고 하죠. 그리고 사소한 딴지를 걸자면 음성 인식률이 아닌 ERR이 25%가 아닐까 생각 합니다... 저도 음성인식 분야에서 일하고 있는데 DNN의 적용과 미적용의 차이는 천지차이죠... 대박입니다... 저도 처음에 NN이 다시 이슈다라고 회사에서 말했을 때에 나이드신 분들의 반응을 똑똑히 기억합니다... 사기라며... 그럴리 없다며... 크크크... 하지만 덕분에 나이드신 분들의 Insight가 다시 한번 빛날 수 있는 계기는 되더라구요... 저는 학교에서 확률 모델을 중요하게 다뤘던 세대라...
15/04/09 09:27
아.. 이 댓글이 저에겐 더 insightful 하네요. 몇년전에 ANN으로 한번 논문쓴적이 있는데 결과가 좀 부실했지만 적당히 포장했던 기억이 있어서.. 저도 왜 이럴까 좀 고민 중이긴 했었습니다.
15/04/09 00:01
이번에 GPU tech conference 갔는데 키노트는 죄다 딥러닝이더군요. 관심 있으신 분은 http://on-demand-gtc.gputechconf.com/gtcnew/on-demand-gtc.php 여기서 한번 봐 보세요.
이미지 인식이나 같은 사람인지 다른 사람인지 구분하는 것은 이미 사람보다 뛰어나다고 합니다. 대회가 열리는데 사람도 참가하는데 (일종의 레퍼런스로...) 최근엔 사람보다 인식률이 좋습니다; 구글플러스에 사진 있으신 분들은 태그 안 해 놨어도 사진 검색이 가능합니다. http://www.androidpolice.com/2013/05/21/googles-best-new-unadvertised-feature-photo-search-with-visual-recognition-try-it-on-your-own-pictures-and-be-amazed/ 그리고 오토캡션이 인상적이었는데 아래 링크에 예가 있습니다. http://techcrunch.com/2014/11/18/new-google-research-project-can-auto-caption-complex-images/ 급하게 찾다보니 죄다 구글인데, 마소나 바이두도 이쪽 분야에 뛰어나다고 들었습니다.
15/04/09 11:33
NVidia가 이 분야의 선도자 역할을 하고 있긴 하지만, ATI나 인텔도 만만치 않습니다.
소위 GPGPU 분야의 문을 열어 제낀건 NVidia의 CUDA였죠. 그러나 MS가 ComputeShader라는걸 만들어내고, OpenCL이라는 공개 라이브러리가 나오고, 인텔의 라라비 프로젝트가 가동되면서, 이제는 NVidia의 전유물이 아니게 되어버렸죠. 딥러닝 분야에 적용되고 있는지까지는 사실 이거 보고 알았는데, 이전에도 물리 시뮬레이션 등에는 흔하게 쓰이고 있었습니다.
15/04/09 11:49
Intel 에서도 병렬 컴퓨팅 관심이 많은가보네요. 근데 제가 알기로는 딥러닝 관련해서는 Nvidia 가 거의 독주하고 있는 것 같습니다. 말씀하신대로 물리, 그래픽 분야를 위해 주로 사용되었던 GPU 가 딥러닝이라는 새로운 시장을 찾은 것 같아요.
15/04/09 00:04
클라우드 컴퓨팅, 빅데이터 분석... 등등의 분야는, 기존의 기술들이 수직적으로 발전한 결과물이 아니라, 새로운 개념의 산물입니다.
아직까지는 사람들이 잘 인식을 못하고 있는 편이지요. 데이터베이스 분야도, 그동안 전통적인 SQL 언어를 벗어난 NoSQL이 각광받고 있고, 실제로 많은 회사들이 도입해서 사용중입니다. 클라우드 컴퓨팅은, 단순히 웹하드의 다른 이름이 아닙니다. 세계 각지에 흩어져있는 여러대의 서버들을 유기적으로 통합하여, 병렬 처리가 가능하고, 내가 어디에서 접속을 하건 비슷한 성능을 제공받을 수 있는 기술이죠. 아직 진행중입니다만... 그리고, 컴퓨터 엔지니어링의 이러한 발전이 인공지능에도 긍정적인 영향을 주게 될겁니다. 예전에는 인공지능 컴퓨터라 하면, 무지막지하게 커다란 고성능 서버가 있어서, 그게 전자뇌의 역할을 하는... 뭐 그런 이미지가 많았죠? 터미네이터나, 매트릭스도 비슷한 형태로 그려지고 있고요. 하지만, 제 예상으론... 전 세계의 데이터센터에 놓여진 서버들이 유기적으로 데이터를 처리하는 병렬 컴퓨팅의 형태가 될 것이라고 예상합니다. 이미 아마존의 AWS, 마이크로소프트의 Azure, 구글의 Google Cloud 등이, 제가 말한것과 비슷한 형태로 발전 중에 있습니다.
15/04/09 00:11
어익후.. 저의 일천한 댓글에... 제가 다 영광입니다.;;;
삼성은... 근처도 못 가봤..;; 아, 한번 삼성전자쪽에 세미나 강연 초청을 받아 가본적은 있긴 하군요. 흐흐...;; 전 그냥.... 쬐깐한 게임회사에서 고군분투하고 있는 게임 프로그래머에 불과합니다. 크크크...
15/04/09 09:23
음. DNA 컴퓨팅은 저도 좀 생소하네요. 10여전전에 서울대 장병탁 교수님이 얘기하셨던 생체 컴퓨팅 세미나에서 들어봤던것 같기도 한데..
아둔한 제 소견으로는 많이 다뤄지는 AI 는 아닌것 같습니다. 제가 더 드릴 수 있는 말씀이 없네요. ^^
15/04/09 06:40
비젼과 머신러닝분야에서 오랫동안 일을 해왔는데, 최근 이분야가 많은 관심을 받는게 내심 반가우면서도 한편 다소 과장된 hype가 좀 우려되기도 한 뭐..그런 복잡한 심정입니다. 그나저나 마술사얀님의 아이디는 마술사 얀 리쿤 은 아니겠죠? ;)
15/04/09 09:20
은영전 얀웬리입니다. ^^
저는 비젼관련해서는 동향 파악만 하는 정도라, 혹시 기회가 되면 현업에 대한 이야기를 듣고 싶네요. 본문에도 썼지만 과장, 호들갑은 Fund 받아야 하는 학문들의 숙명인가봅니다. 그런데 대체로 딥러닝 처음 도입하는 사람들에게도 좋은 반응이 나오고 있는데 우려할정도의 과열 분위기인지도 궁금해지네요.
15/04/09 09:18
저도 이미지로 먹고 사는 사람이라.. SVM과 ANN 비교하는 국책연구 좀 하는 중인데.. ANN 의미도 없는거 그만하자고 하다가.. 딥러닝 때문에 좀 고민중입니다. 뭐 굳이 이번 연차에 여길 발댈 필요는 없지만.. 다른걸로는 딥러닝에 한발 걸치고는 있고요.. 최근 며칠새 회사도 두군데 컨택했는데.. 확실히 initial hype가 강하게 느껴지긴 합니다만.. (비트코인의 그것느낌도 나고요..) 회사까지 차려서 빨리 성과낼 분야가 있을까에는 좀은 회의적이네요. 아직은 연구실이나 대학 베이스가 맞는게 아닐런지..
15/04/09 09:29
저도 딥러닝 관련해서 스타트업 할만한게 뭐가 있을까 생각해봤습니다. 사실 딥러닝 관련해서는 open source 도 많고 구현이 어려운게 아니라고 보이는데. 문제는 빅데이터 확보라고 봅니다. 저는 딥러닝 자체를 이용해서 무언가 해보는 것도 좋지만, 딥러닝에 관심이 있는 군소 업체를 위한 빅데이터 제공 사업이 나름 전망이 있지 않을까 생각이 들더군요. 그리고 진짜 딥러닝이 전망이 있다고 판단되면 아예 딥러닝 컨설던트도 나쁘지 않을것 같습니다. 아무래도 초기 신경망 설계는 문외한이 해보기엔 시행착오가 많을 것 같아서 니즈가 있을것 같네요.
15/04/09 09:38
그런 인상을 받긴 했어요. 의료영상 자료는 IRB가 있어서 사실 함부로 돌릴 수는 없지만.. 자료만 있으면 뭔가를 보여주겠다.. 라는 강한 '열정'이 윗사람들에게 어필을 했나 보더군요. 저는 설마..싶습니다만..여튼 이쪽도 공개된 db가 있고 컴피티션 해서 결과 올리는 워킹그룹도 있고 해서 그쪽을 소개시켜 줬습니다만. 여튼 몇년 동안 여러사람들이 '꽤 해먹겠네' 하는 느낌은 분명히 듭니다.
15/04/09 16:53
맞아요. BigData 확보를 하는 스타트업이 굉장히 좋은 것 같습니다.
예를 들면 플리토라는 앱이 있습니다. 대역 Corpus를 얻기에 이만한 컨텐츠가 없지요. 구글 등 여러군데에서 투자를 받은 것으로 알고 있어요.
15/04/09 10:01
아.. 근데 제가 생각했던 글타래는 일반인들 대상으로 하는 그저 교양 인공지능 소개글입니다. 신경망은 이정도로 마무리 할까 해요. 죄송합니다. 나중에 기술적으로 더 들어간 번외편에 언급될 수도 있을지 모르겠네요. T.T
15/04/09 11:58
Layer 하나를 추가해서 Big Data 의 복잡한 특성을 포용할 그릇을 마련해준 장점이 있는 반면..
학습 모델 스페이스(?)가 엄청나게 복잡해져서 이제 모델을 학습 시키는게 어마어마하게 어려워졌습니다.. 수집된 학습데이터가 아주 잘 구성되서 이 복잡한 모델을 학습시키는데 문제가 없는 분야들도 꽤 있지만... 데이터가 충분하지 않은 많은 분야에 대해 적용하기에는 모델 학습이 엄청 어려워지는 단점이 생겼습니다.. SVM 같은 Shallow(?) Learning 에서 적절히 학습시키는 것과는 난이도에서 비교도 안되죠.. 그렇다고 잘 구성된 빅데이터를 구하기 힘든 분야에서는 딥러닝 방식을 포기할꺼냐? 그러기에는 딥러닝이 보여준 성능의 향상이 너무 커서 절대 포기하기가 어려울껍니다.. 결국 딥러닝이 가능하도록 학습데이터를 잘 구성하는쪽으로 집중하거나.,... 아니면 부족한 데이터도 가능하도록 딥러닝 모델을 효과적으로 만들거나... 이렇게 두 부분으로 발전하지 않을까 하네요...
15/04/09 12:10
부족한 데이터로 효과적인 학습을 하려는 시도는 사실 20년동안 해오던거라, 딱히 답이 나올것 같지가 않습니다.
결국 어떤수를 써서라도 빅데이터를 확보하는게 관건으로 보입니다. 빅데이터 시장이 곧 폭발할것 같습니다.
15/04/09 12:56
많은 분야에서 데이터들은 Shallow Learning 을 하기에는 충분하지만 Deep Learning 을 하기에는 부족한 데이터죠
그걸 단순히 빅데이터를 만들어야만 Deep Learning 을 쓸수 있다면 너무 비효율적이죠.. 그래서 효율적으로 조금만 늘이면 될지 또는 reuse 를 할지 등등 비교적(?) 새로운 이슈가 나온거죠..
|
||||||||||